1. jsoup 라이브러리로 크롤링하기
이제 자바로 만들어진 HTML parser*인 jsoup 라이브러리를 사용하여 크롤링을 해보자.
jsoup 라이브러리는 DOM 구조를 추적하거나 CSS 선택자를 사용하여 데이터를 찾아 추출하는 기능이다.
* parser : 인터프리터나 컴파일러의 구성 요소 가운데 하나로, 입력 토큰에 내재된 자료 구조를 빌드하고 문법을 검사하는 도구이다.
다운로드는 아래의 사이트에서 할 수 있다.
Download and install jsoup
Download and install jsoup jsoup is available as a downloadable .jar java library. The current release version is 1.15.3. What's new See the 1.15.3 release announcement for the latest changes, or the changelog for the full history. Previous releases of jso
jsoup.org
2. 프로젝트를 만들고 외부라이브러리 추가하기
이제 자바로 Dynamic Web Project를 생성하고 라이브러리를 추가해보자.
우선 프로젝트를 하나 생성해주었다.
그리고 이제 위의 사이트에서 다운로드 받아온 라이브러리 파일을 넣어주어야한다.
어디에?
위의 사진의 하단을 보면 있는 lib 폴더에 넣으면 된다.
* 여기서 lib 폴더의 이름이 눈에 익지 않은가? library의 줄임말이다.
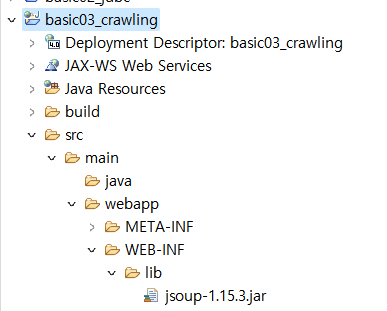
jsoup 라이브러리가 잘 추가되었다.
3. jsoup 라이브러리의 핵심 클래스는 알고 가자
jsoup 라이브러리를 사용하기 전에 jsoup이 갖고 있는 여러 클래스 중 그래도 꼭 알고 넘어가야하는 핵심 클래스만 짚고 넘어가자.
1) Document 클래스
: 연결해서 얻어온 HTML 전체 문서
2) Elements 클래스
: Element가 모인 자료형
3) Element 클래스
: Document의 HTML 요소
jsoup에서 사용하는 다른 여러 api 들은 아래의 사이트를 참조하면 된다.
참조 : https://jsoup.org/apidocs/
Overview (jsoup Java HTML Parser 1.15.3 API)
jsoup: Java HTML parser that makes sense of real-world HTML soup. jsoup is a Java library for working with real-world HTML. It provides a very convenient API for fetching URLs and extracting and manipulating data, using the best of HTML5 DOM methods and CS
jsoup.org
4. jsoup 라이브러리로 크롤링하기
이제 본격적으로 크롤링을 해보자.
강사님은 중앙정보처리학원 웹페이지의 공지사항 제목을 크롤링해보자고 하셨다.
1) URL 담기
먼저 공지사항 페이지의 주소를 String 자료형의 URL 변수에 담았다.
String URL = "https://www.choongang.co.kr/html/sub07_01_n.php";
2) 웹페이지 소스 가져오기
그리고 페이지의 소스를 가져왔다.
여기서 사용되는 jsoup 라이브러리의 클래스들을 확인해두자.
우선 코드는 아래와 같다.
Document doc = Jsoup.connect(URL).get();
System.out.println(doc);
- Jsoup.connect(주소) : 페이지 주소의 문자열을 주소화 한다.
- get() : 주소화된 페이지의 주소를 가져온다.
출력하면 아래와 같이 나온다.

페이지 소스를 불러올 수 있다면 여기에서 우린 공지사항 제목을 뽑아내면 되는 것이다.
그런데!!! 이 사이트의 공지사항은 총 11페이지다.
우리가 긁어온 페이지는 단 1페이지의 페이지 소스.
어떻게 해야할까?
페이지의 유사성을 파악해서 반복문 처리를 하면 된다.
String URL = "https://www.choongang.co.kr/html/sub07_01_n.php?page=1&mod=&idx=";
// 1~11 웹페이지 소스 가져오기
for(int p=1; p<=11; p++) {
String params = "?page=" + p + "&mod=&idx=";
//System.out.println(params);
Document doc = Jsoup.connect(URL+params).get();
System.out.println(doc);
} // for end
3) 공지사항 제목 가져오기
// 요소 선택하기
/*
<td class="default_title">[22년 9월 02일] 9월 기업인 초청 취업 특강</td>
*/
Elements elements = doc.select(".default_title");
for( Element element : elements ) {
System.out.println(element.text());
} // for end- Elements 클래스
- .select() : Document 클래스로 담은 HTML문의 CSS 쿼리문을 불러오는 기능이다. 여기선 .default_title을 썻기에 default_title이라는 클래스를 불러오는 코드이다.
- Element 클래스
- .text() : Element 클래스로 담아진 각각의 요소를 텍스트화한다.

4) 파일로 저장하기
자바에서 사용하는 입출력 스트림을 활용하여 크롤링된 결과물을 파일로 저장할 수도 있다.
이에 대한 내용은 아래의 게시물에서 확인하면 된다.
참조 : https://ddcloud.tistory.com/141
[JAVA] #10-3 입출력스트림 : 출력(Output)
1. 출력 시키기 입력하는 방법을 배웠으니 이번엔 출력이다! 우선 출력은 어디에 출력을 할 것인가가 중요하다. 그리고 그 파일이 실제로 있는지 없는지에 따라서도 다르게 동작한다. 입력
ddcloud.tistory.com
전체 코드는 다음과 같다.
package crawling0923;
import java.io.FileWriter;
import java.io.PrintWriter;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test04_choongang {
public static void main(String[] args) {
// 중앙정보처리학원 웹페이지의 공지사항 제목만 크롤링해서 파일에 저장하기
try {
String fileName = "C:/java202207/choongang.txt";
FileWriter fw = new FileWriter(fileName, true); // 추가모드
PrintWriter out = new PrintWriter(fw, true);
String URL = "https://www.choongang.co.kr/html/sub07_01_n.php";
for(int p=1; p<=11; p++) {
String params = "?page=" + p + "&mod=&idx=";
Document doc = Jsoup.connect(URL+params).get();
Elements elements = doc.select(".board_default_list .default_title");
for( Element element : elements ) {
out.println(element.text());
} // for end
} // for end
System.out.println("choongang.txt 파일 완성!");
} catch (Exception e) {
System.out.println("크롤링 실패 : " + e);
} // end
} // main() end
} // class end
'⁂ Java > : Crawling' 카테고리의 다른 글
| [JAVA] 웹 크롤링(Web Crawling) 1 : 웹크롤링 이해하기 (0) | 2022.09.23 |
|---|