1. index
1) 개념
- 더 빠른 검색을 위한 인덱스
- 데이터를 빠르게 찾을 수 있는 수단
- 테이블에 대한 조회 속도를 높여 주는 자료구조
- PK칼럼은 자동으로 인덱스 생성된다
2) 방식
- full scan
처음부터 끝까지 일일이 검사하는 방법. 전수조사
- index range scan
이름이 여러개인 경우 목차를 찾아서 페이지를 찾아감
훨씬 빠름. 별도의 메모리가 있어야 함.
- index unique scan
학번은 1개만 존재함. 유일한 값
3) 인덱스 생성
형식) create index 인덱스명 on 테이블명(칼럼명)
4) 인덱스 삭제
형식) drop index 인덱스명
2. index 연습하기
1) emp2 테이블 만들기
--테이블생성
create table emp2(
id number(5)
,name varchar2(25)
,salary number(7, 2)
,phone varchar2(15)
,dept_id number(7)
);
--행추가
insert into emp2(id,name) values (10,'kim');
insert into emp2(id,name) values (20,'park');
insert into emp2(id,name) values (30,'hong');
commit;
2) index를 만들고 전 후 비교하기
-- 인덱스 생성 전
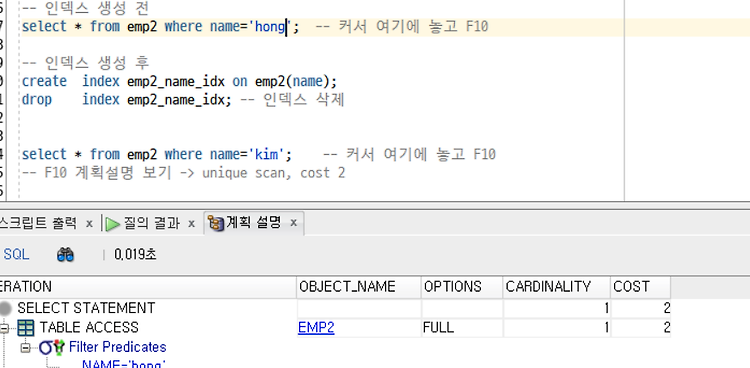
select * from emp2 where name='hong'; -- 커서 여기에 놓고 F10
-- 인덱스 생성 후
create index emp2_name_idx on emp2(name);
drop index emp2_name_idx on emp2(name); -- 인덱스 삭제
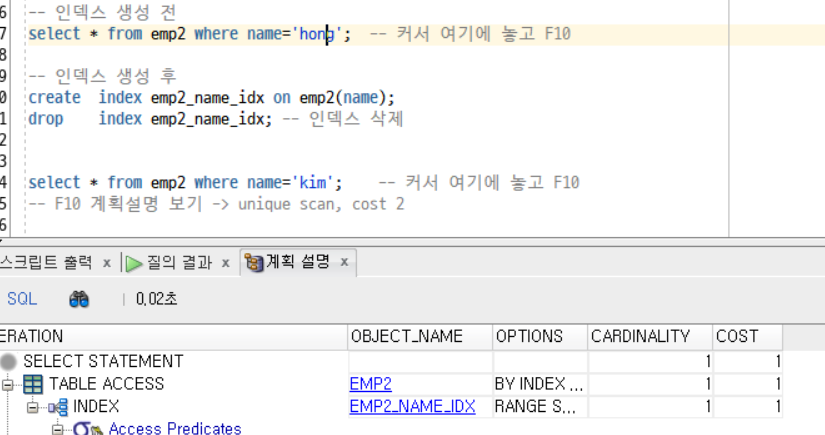
select * from emp2 where name='kim'; -- 커서 여기에 놓고 F10
-- F10 계획설명 보기 -> unique scan, cost 2

* 여기서 COST란 무엇일까!? *
Oracle Optimizer라는 것이 있다.
사용자가 실행하는 SQL에 대하여 가장 적절한 데이터 추출 경로가 무엇인가를 결정하는 Oracle 내부 아키텍처이다.
Oracle Optimizer는 크게 규칙기반(Rule-base)과 비용기반(Cost-based)으로 나누어 지는데 규칙기반(Rule-based)은 Oracle 데이터베이스 시스템이 미리 정해놓은 일정한 순위대로 실행이 된다.
비용기반(Cost-based)은 분석된 데이터베이스 현재 상태를 기반으로 비용이 가장 적게 드는 실행 경로(Execution plan)를 채택하여 실행한다.
일반적으로 비용기반(Cost-based) 접근이 규칙기반(Rule-based) 접근보다 나은 실행 계획을 제공하는데 비용기반접근을 통해 Oracle Optimizer가 실행 계획을 얻기 위해서는 통계 정보가 필요하다.
인덱스를 부여하자 COST가 2에서 1로 줄어드는 것을 볼 수 있다.
오라클에서 보다 더 나은 데이터 접근이 가능하다는 뜻이다.
3) PK가 있는 테이블
PK는 인덱스가 자동으로 생성되면서 정렬된다.
create table emp3 (
no number primary key
,name varchar2(10)
,sal number
);
select * from emp3 where no=3;
-- F10 계획설명 보기 -> unique scan, cost 1
3. 100만건의 레코드 대상으로 COST 비교하기
1) 테이블 만들기
create table emp4(
no number
,name varchar2(10)
,sal number
);
2) 프로시저를 이용해서 100만행 추가하기
declare -- 선언문
-- 변수 선언
i number := 1; -- i변수에 1 대입, := 연산자
name varchar2(20) := 'kim';
sal number := 0;
begin
-- T-SQL문
while i<=1000000 loop
if i mod 2 = 0 then
name := 'kim' || to_char(i);
sal := 300;
elsif i mod 3 = 0 then
name := 'park' || to_char(i);
sal := 400;
elsif i mod 4 = 0 then
name := 'hong' || to_char(i);
sal := 500;
else
name := 'shin' || to_char(i);
sal := 250;
end if;
insert into emp4(no, name, sal) values (i, name, sal); -- 행추가
i := i+1;
end loop;
end;
3) 인덱스 사용 전후 비교하기
- 인덱스 사용 전
select * from emp4 where name='kim466'; -- 실행하고 난 후, 여기에 커서 놓고 F10 계획 설명
-- FULL scan, COST 893
select * from emp4 where no=466; -- FULL scan, COST 892
select * from emp4 where sal>300; -- FULL scan, COST 893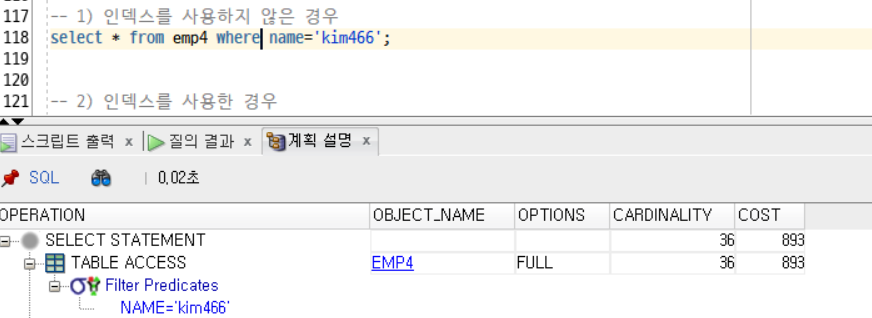
- 인덱스 사용 후
create index emp4_name_idx on emp4(name);
select * from emp4 where name='kim466';

이와 같이 COST가 확 내려가는 것을 볼 수 있다.
인덱스가 개별로 붙었기 때문이다.
* 두 개의 칼럼을 기준으로 인덱스 생성하기
create index emp4_name_sal_idx on emp4(name, sal);
select * from emp4 where name='kim466' and sal>200; -- RANGE scan, COST 3
'⁂ Oracle DB > : 기본 익히기' 카테고리의 다른 글
| [Oracle] #6-4 프로시져(PL/SQL (Procedural Language)) (0) | 2022.08.30 |
|---|---|
| [Oracle] #6-3 뷰(View) (0) | 2022.08.30 |
| [Oracle] #6-2 계정 생성하기(dbf 파일 만들기, grant) (0) | 2022.08.30 |
| [Oracle] #6-1 SQL Developer로 CSV파일 가져오기 (0) | 2022.08.29 |
| [Oracle] #5-3 rownum으로 페이징하기 (0) | 2022.08.29 |